




Datele: combustibilul fără de care AI nu pornește
Secțiunea 2 · Lecția 2 — Datele: combustibilul fără de care AI nu pornește
Dacă AI este “motorul”, datele sunt combustibilul și uleiul în același timp. Poți avea cel mai bun model din lume — dacă datele sunt incomplete, haotice sau greu de accesat, AI fie nu pornește, fie pornește și “dă rateuri”.
În lecția asta înțelegi, practic și clar: ce tipuri de date contează, cum le pregătești, cum eviți capcana “avem multe date” și cum transformi datele dintr-o problemă tehnică într-un avantaj competitiv.
0) Paradoxul companiilor: “avem multe date” și totuși nu putem face AI
Foarte multe companii sunt în situația asta: au ERP, CRM, ticketing, analytics, BI, Excel-uri, rapoarte, emailuri, documente, SharePoint, drive-uri… și totuși, când vrei să faci un proiect AI, apare replica: “nu avem date”.
În 90% din cazuri, problema nu este lipsa datelor, ci una dintre acestea:
- datele nu sunt accesibile (permisiuni, silozuri, tool-uri diferite)
- datele nu sunt comparabile (definiții diferite, perioade diferite, “versiuni” diferite)
- datele nu sunt curate (lipsuri, duplicate, erori, câmpuri libere pline de improvizații)
- nu există “adevăr” (nu ai etichete / outcome clar pentru ce vrei să prezici)
- nu există ownership (nimeni nu răspunde de calitate și de definiții)
Deci lecția cheie: proiectul AI nu începe cu “modelul”. Începe cu data readiness. Dacă vrei rezultate, prima investiție este disciplina datelor.
“Avem date” nu înseamnă nimic. “Avem date utilizabile pentru decizia X, cu definiții, calitate și acces” înseamnă tot.
🎬 Mică scenă: pilotul AI moare dintr-un motiv banal
Echipa pornește un pilot “AI pentru churn”. După 3 săptămâni, descoperă că: nu există o definiție unică de churn, statusurile din CRM sunt folosite diferit pe regiuni, iar datele despre “ultima interacțiune” sunt în email, nu în sistem.
Modelul nu e problema. Problema e că “adevărul” nu e definit, iar datele nu spun aceeași poveste.
Dacă “churn” nu e definit, orice model devine un generator de opinii, nu de decizii.
1) Tipuri de date: ce contează cu adevărat pentru AI în business
În practică, datele care hrănesc AI se împart în câteva categorii mari. Important este să înțelegi că nu toate au aceeași valoare și nu toate sunt la fel de ușor de folosit.
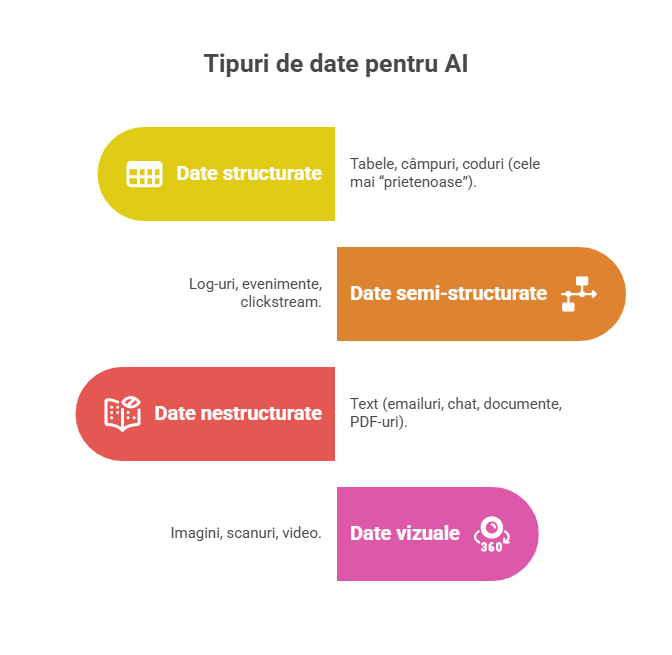
📦 Date structurate: tabele, câmpuri, coduri (cele mai “prietenoase”)
Sunt datele din ERP/CRM: tranzacții, comenzi, facturi, statusuri, date clienți, produse, prețuri, termene. Aici AI clasic strălucește: scoring, predicție, clasificare.
- Pro: ușor de măsurat și de automatizat
- Contra: pot fi “false precise” dacă definițiile sunt diferite (ex: “client activ”)
🧾 Date semi-structurate: log-uri, evenimente, clickstream
Sunt datele de “comportament”: pagini vizitate, secvențe de acțiuni, evenimente în aplicație, timpi, erori, sesiuni. Sunt excelente pentru: funnel optimization, fraud signals, next best action.
- Pro: volum mare, semnale timpurii
- Contra: interpretarea poate fi tricky (“a stat 2 minute” nu înseamnă automat interes)
📝 Date nestructurate: text (emailuri, chat, documente, PDF-uri)
Aici intră AI generativ și NLP: rezumate, extragere de informații, clasificare de tichete, voice-of-customer. Problema: textul e haotic și “adevărul” e greu de etichetat.
- Pro: este aur ascuns (cunoștințe, motive, probleme, cerințe)
- Contra: confidențialitate, curățare, bias, risc de inventare dacă nu ai surse
Pentru text, cheia este: sursă + citare internă + constrângeri. Fără asta, ai “păreri frumoase”.
🖼️ Date vizuale: imagini, scanuri, video
Se folosesc pentru: recunoaștere documente, verificare identitate, inspecții, defecte, inventar. În business, apar mai rar decât textul/cifrele, dar pot avea ROI mare în operațiuni.
2) “Adevărul” (label-ul): piesa care separă AI-ul util de AI-ul decorativ
În AI predictiv, ai nevoie de un rezultat clar: ce vrei să prezici?
Asta se numește “label” sau “outcome”.
Exemplu: “churn = clientul a plecat”, “default = întârziere > 90 zile”, “lead bun = a cumpărat în 30 zile”.
Problema clasică în business: label-ul este definit prost.
De exemplu:
- “Lead bun” = “lead aprobat de sales” (nu “lead care a cumpărat”) → modelul învață preferințele oamenilor, nu adevărul
- “Ticket rezolvat” = “ticket închis” (nu “client mulțumit”) → optimizezi închiderea, nu satisfacția
- “Client profitabil” = “client cu venit mare” (dar cu risc și costuri mari) → optimizezi greșit
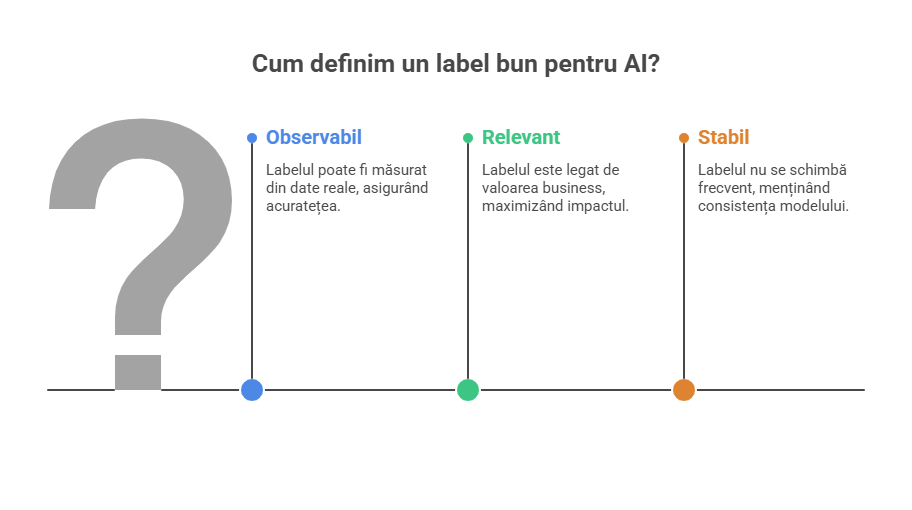
✅ Cum definești un label bun (3 criterii simple)
- Observabil: îl poți măsura din date reale (nu din presupuneri).
- Relevant: are legătură directă cu valoarea business (venit, cost, risc, SLA).
- Stabil: nu se schimbă definirea în fiecare trimestru (altfel modelul se rupe).
Dacă label-ul e slab, AI-ul devine un “amplificator de confuzie”.
3) Calitatea datelor: 6 dimensiuni care contează (și cum le simți imediat)
Calitatea datelor nu înseamnă “să fie frumos”. Înseamnă să fie util pentru decizia pe care o iei. Cele mai importante dimensiuni (cu impact direct în AI) sunt:
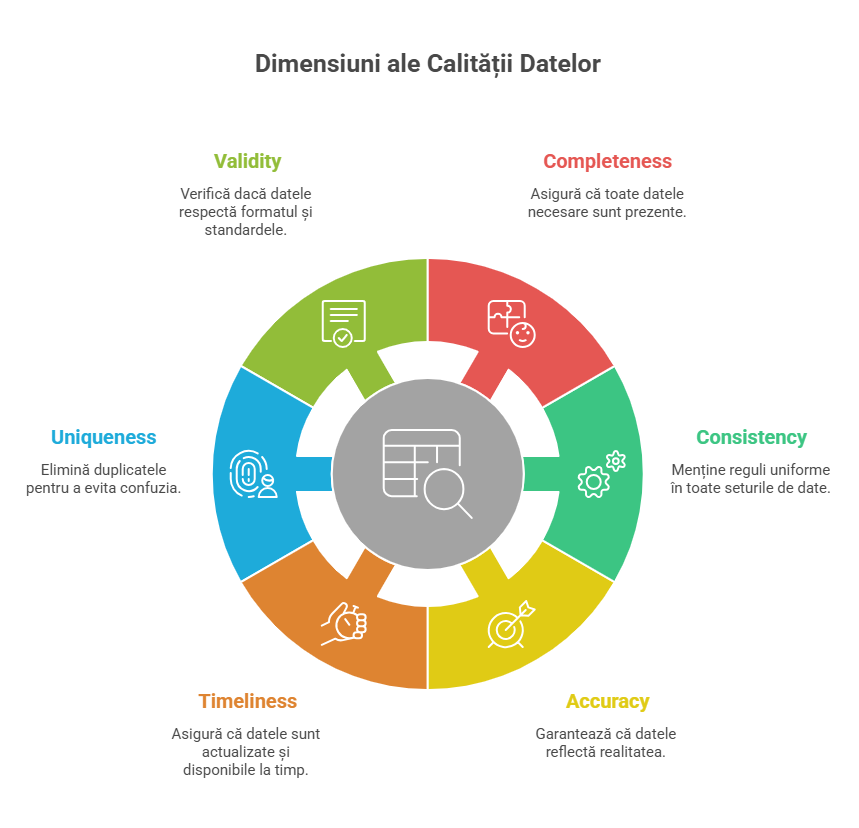
🧪 6 dimensiuni de calitate (cu exemple practice)
- Completeness: câte lipsuri ai? (ex: lipsesc date de contact la 40% din clienți)
- Consistency: aceeași regulă peste tot? (ex: “status activ” folosit diferit pe regiuni)
- Accuracy: reflectă realitatea? (ex: adrese vechi, cifre rotunjite, erori de introducere)
- Timeliness: cât de repede ajunge informația? (ex: update după 2 săptămâni = useless pentru EWS)
- Uniqueness: duplicate? (ex: același client apare de 3 ori)
- Validity: respectă formatul? (ex: CUI în câmp de text cu spații și caractere)
4) Data pipeline: cum treci de la “surse” la “date utilizabile” (fără să devii sclavul curățării)
Un pipeline bun este un flux repetabil. Nu un proiect “o dată”. În business, pipeline-ul minim arată așa:
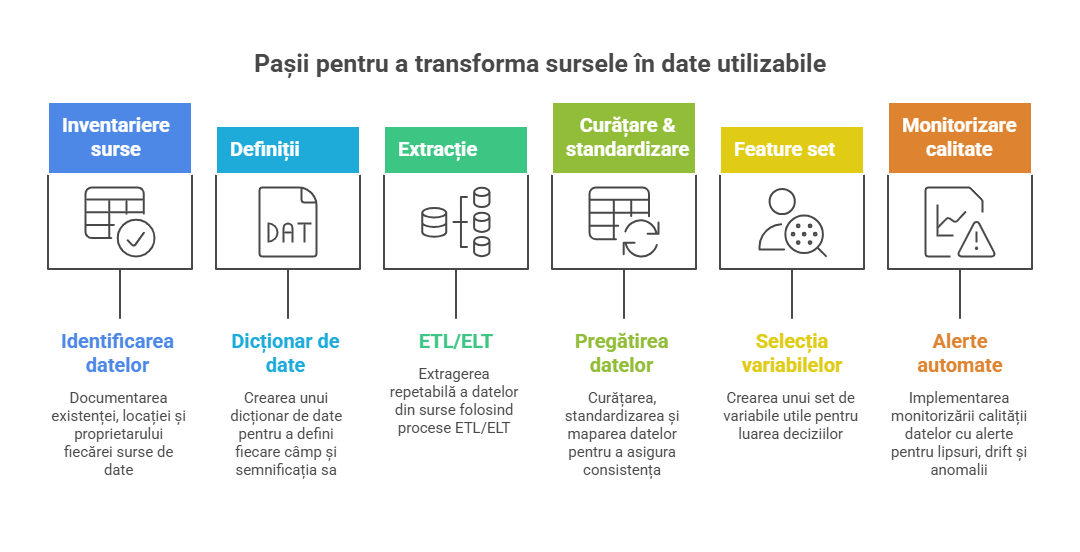
- Inventariere surse (ce există, unde, cine e owner)
- Definiții (dicționar de date: ce înseamnă fiecare câmp)
- Extracție (ETL/ELT: scoți datele în mod repetabil)
- Curățare & standardizare (format, duplicate, mapping)
- Feature set (variabile utile pentru decizia ta)
- Monitorizare calitate (alerte: lipsuri, drift, anomalii)
🧠 De retinut: “feature” = traducerea business-ului în semnale
În proiectele AI, variabilele (features) sunt locul unde business-ul devine matematică fără să simți.
Exemple:
- “Client instabil” → variație mare în volume lunare
- “Interes ridicat” → frecvență mare de interacțiuni + timp scurt între contact și achiziție
- “Risc operațional” → număr de incidente + severitate + timpi de rezolvare
Feature engineering bun = înțelegere bună a procesului. Nu e “tehnică”. E business tradus.
5) Date pentru AI generativ: RAG, surse și “nu inventa”
În AI generativ, datele sunt alt tip de combustibil: nu doar “tabele”, ci și cunoaștere. Ai 3 moduri sănătoase de a alimenta un LLM cu informație reală:
📚 3 moduri de a pune cunoaștere în LLM (pe scurt și practic)
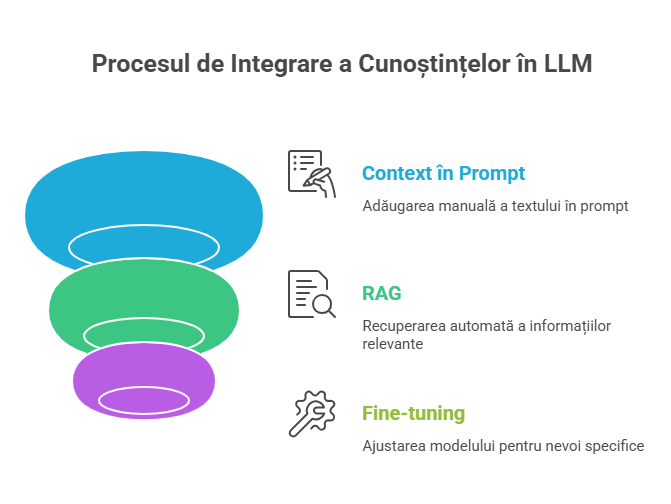
1) Context în prompt (manual, mic)
Pui un fragment de text în prompt și ceri rezumat/extragere. Bun pentru task-uri mici, dar nu scalabil.
2) RAG (Retrieval-Augmented Generation)
Sistemul caută în documente interne (policy, proceduri, FAQ) și aduce fragmente relevante în prompt.
Modelul răspunde “sprijinit” pe surse. Aici scade riscul de inventare.
3) Fine-tuning (rar necesar pentru business general)
Ajustezi modelul pentru stil/format specific. Util în unele cazuri, dar de multe ori RAG + prompt engineering e suficient.
Dacă vrei răspunsuri corecte pe politici/proceduri interne, RAG este “default-ul” sănătos.
🛡️ Guardrails pentru LLM în companie (minimul minim)
- Surse: răspunde doar pe baza documentelor furnizate / indexate.
- Refuz controlat: dacă nu găsește surse, spune “nu știu” + cere clarificare.
- Citare internă: indică pagină/fragment (în interfață internă) pentru audit.
- Redaction: maschează date sensibile (PII) în log-uri și prompt-uri.
- Role-based access: nu toate documentele pentru toată lumea.
LLM fără surse + fără refuz controlat = “generator de răspunsuri plauzibile”, nu “assistant de business”.
6) Data governance pe scurt: cine răspunde, cum standardizezi, cum nu mori în comitete
“Guvernanță” sperie. În practică, guvernanța minimă pentru AI înseamnă 4 lucruri: dicționar, owner, reguli de calitate, rutină de revizuire.
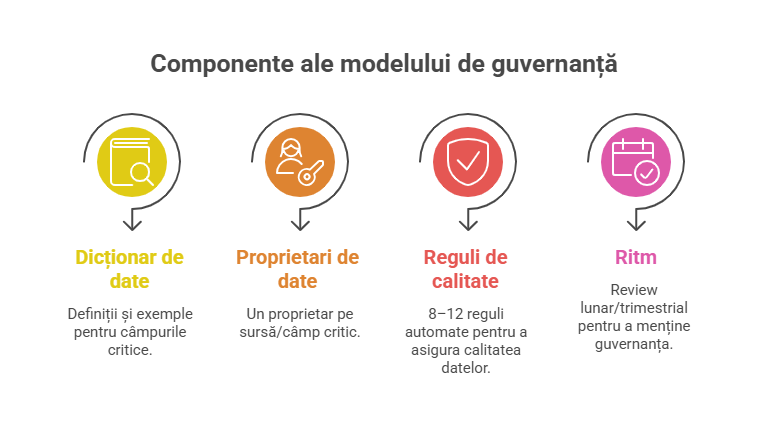
✅ Model minim de guvernanță (care chiar funcționează)
- Data dictionary: ce înseamnă câmpurile critice (definiții + exemple).
- Data owners: un owner pe sursă/câmp critic (nu “toți”).
- Quality rules: 8–12 reguli automate (ex: lipsuri > 5% = alertă).
- Ritm: review lunar/trimestrial (nu “când avem timp”).
7) AI ca instrument pentru date: cum folosești AI să-ți curețe și explice datele (fără să le “inventeze”)
Da, AI poate ajuta chiar la problema datelor, dacă o folosești corect. Unde are impact:
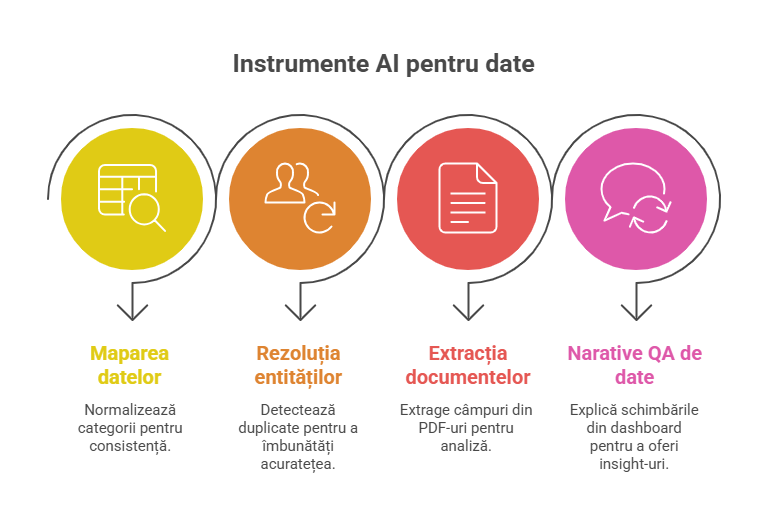
- Data mapping: normalizează categorii (ex: “Bucuresti”, “București”, “Buc.”)
- Entity resolution: detectează duplicate (același client cu nume diferit)
- Document extraction: extrage câmpuri din PDF-uri (facturi, contracte)
- Data QA narratives: explică ce s-a schimbat într-un dashboard (“lipsuri au crescut pe sursa X”)
🤖 Prompt-uri “safe” pentru lucru cu date (fără inventare)
„Am o coloană cu valori neuniforme (mai jos). Propune un mapping către valori standard.
Reguli:
– NU inventa categorii noi
– Propune max 10 categorii standard
– Pentru fiecare valoare originală, spune categoria standard + motiv scurt.”
PROMPT B — Detectare probleme de calitate:
„Iată un rezumat al calității datelor (missing %, duplicate %, outliers). Identifică top 5 riscuri de interpretare și propune reguli simple (if/then) de monitorizare.”
PROMPT C — Generare dicționar de date:
„Pe baza listei de câmpuri de mai jos, propune un data dictionary:
– Definiție
– Unitate/format
– Exemple valide/invalid
– Owner recomandat
NU inventa surse de date. Folosește doar câmpurile date.”
PROMPT D — Rezumat pentru management:
„Scrie un rezumat scurt (max 10 bullet-uri) despre starea datelor: ce e ok, ce e critic, ce acțiuni propui (owner + deadline).
Ton: direct, fără jargon.”
AI este bun la “ordonat și explicat”. Nu-l lăsa să “completeze” ce nu există.
8) Exercițiu: Data readiness checklist pentru un use case din compania ta
Înainte să alegi model, fă acest exercițiu. Te scutește de 70% din eșecuri.
🧪 Exercițiu (template complet): “Suntem pregătiți pentru AI?”
A) Decizia (claritate)
– Ce decizie vrei? ______________________
– Output: scor / clasă / text / recomandare: ______________________
B) Label / adevăr (pentru predictiv)
– Care e outcome? ______________________
– Există în date? DA/NU
– Definiție stabilă? DA/NU
C) Surse & acces
– Surse: ______________________
– Avem acces repetabil? DA/NU
– Owner pe sursă? DA/NU
D) Calitate (estimativ)
– Missing %: ______
– Duplicate %: ______
– Consistency (1-5): ______
– Timeliness (1-5): ______
E) Guvernanță minimă
– Data dictionary există? DA/NU
– Reguli QA (8–12) există? DA/NU
– Ritm review (lunar/trimestrial): ______________________
F) Risc & guardrails
– Date sensibile? (PII) DA/NU
– Acces pe roluri? DA/NU
– Fallback când AI nu știe? DA/NU
Vezi răspuns orientativ (cum arată “pregătit”)
“Pregătit” nu înseamnă perfect. Înseamnă: decizie clară, label definit, acces repetabil la surse,
calitate suficientă (și monitorizată), ownership, plus guardrails pentru date sensibile.
Cel mai mare ROI vine când transformi data readiness într-o rutină, nu într-un efort eroic înainte de fiecare proiect.
9) Mini-quiz (consolidare) — răspunsurile sunt ascunse
Țintă: 4-6 minute.
Vezi răspuns
Vezi răspuns
Vezi răspuns
Vezi răspuns
10) Checklist de final (output-ul lecției)
- Înțeleg tipurile de date (structurate, semi, nestructurate, vizuale) și ce pot produce în AI.
- Știu ce este un label/outcome și cum îl definesc corect pentru AI predictiv.
- Pot evalua calitatea datelor în 6 dimensiuni și pot defini reguli QA.
- Înțeleg pipeline-ul minim: surse → definiții → extracție → curățare → features → monitorizare.
- Știu cum funcționează RAG pentru LLM și ce guardrails trebuie.
- Am un Data Readiness Checklist și prompt-uri “safe” pentru lucru cu date.
Recap rapid (de ținut minte)
Datele sunt diferența dintre AI “demo” și AI “în producție”.
Nu volumul contează, ci accesul repetabil, definițiile, label-ul, calitatea și guvernanța.
Pentru AI predictiv, label-ul este cheia: dacă e definit prost, modelul optimizează greșit.
Pentru AI generativ, datele înseamnă cunoaștere: folosești RAG și guardrails ca să reduci inventarea.
Când ai pipeline și rutină de calitate, AI devine scalabil și predictibil.
🏷️ Label
🧼 Calitate
🔁 Pipeline
📚 RAG
Să începi cu “modelul” înainte să ai decizia, label-ul și datele pregătite. Vei construi un motor fără combustibil și vei spune că “AI nu merge”.
📝 Mini-quiz final (3-5 minute)
Vezi răspuns
Vezi răspuns
Vezi răspuns